2025-04-21
一个并没有什么用的,纯做针对性扫盲和复习.
机器学习
KNN
为有监督无参方法. 但是有超参 \(k\)(要选奇数) 和距离函数(metric distance).
聚类
K means 聚类:先随几个点,然后聚类之后,然后每个类再选取中心,再聚类,循环往复. 对初始化过于敏感. 需要初始种子尽量远离,并尝试不同的初始种子. 对 outlier 非常敏感.
Validation
划分为训练集,验证集,测试集. 可采用 Cross Validation.
最大似然
\(x\) 独立同分布(iid)采样于模型 \(\theta\),则 \(p(X\mid \theta)=\prod p(x_i\mid \theta)\),取 log 得到 \(\sum \log p(x_i\mid \theta)\).
log 的原因:很多 \(p\) 相乘太小了,精度不够. 取 \(\theta_{MLE}=\arg\max \sum \log p(x_i\mid \theta)\).
最大后验概率
将数据看作参数,\(\theta\) 采样自一个分布. 则 \(p(\theta\mid X)=\frac{p(X\mid \theta)p(\theta)}{p(X)}\),正比于 \(p(X\mid \theta)p(\theta)\),即 \(\theta_{MAP}=\arg\max p(X\mid \theta)p(\theta)\). 比如可以用于对 \(\theta\) 加正则化.
线性回归
\(\frac{1}{n}(A\beta-Y)^{T}(A\beta-Y)\),求导后可知 \(\beta=(A^{T}A)^{-1}A^TY\).
用 MAP 理解来说,若 \(A^{T}A\) 不可逆则加入正则化 \(\lambda ||\beta||^2\),于是变成 \((A^{T}A+\lambda I )^{-1}A^TY\). 这个正则化限制了让所有参数都尽量小.
而用 L1 正则化,则让尽量多的元素为 \(0\).
深度学习
目标检测
在 Faster R-CNN 提出了用 Region Proposal Network 代替 Selective Search 做 Regional Proposal.
YOLO:将目标检测问题看作回归问题,分成很多个格子每个格子做回归问题.
图像分割:Semantic & Instance. 使用 UNet(反卷积 + Skip Connection)是像素级分类问题.s
CNN
感受野计算公式:\(l_k=l_{k-1}+((f_k-1)\prod_{i=1}^{k-1}s_i)\),其中 \(s_i\) 为 stride 大小.
Transformer
不考.
无监督学习:聚类,降维,密度估计,K-Mean,GAN,Auto Encoder
密度估计的 loss 使用 NLL loss.
逻辑回归:做分类任务,损失函数用交叉熵,比均方梯度更大. 二分类输出用 Sigmoid 压缩到 \([0,1]\) 之间;多分类用 Softmax 作为模型输出.
Sigmoid 的组合意义:\(y=\frac{1}{1+e^{-x}}\),则 \(\log \frac{y}{1-y}=x\).
使用 NLL 而非 square error 的原因是因为前者梯度更大. 并且 square error 的梯度有 \(\theta(x)(1-\theta(x))\) 项,在两端的时候梯度最应该大的时候梯度反而接近 0.
偏置的意义:决策边界可以上下调整,不用经过 origin.
Tanh:\(f(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\).
SoftMax 激活函数涉及多个数值,其他函数只作用于一个数值.
精度率(Precision):关心假阳性. 召回率(Recall):关心假阴性. Average Precision :P-R 曲线的面积.
R-CNN :Selective Search 找方格,然后调整为固定大小后每个单独输给 VGG 跑结果,通过回归得到边界框位置.
SPP Net :整个图像输入到 CNN 提取局部特征,Selective Search,然后使用空间金字塔池化(SPP)调整为相同尺寸,通过回归得到边界框位置.
Fast R-CNN :改用 ROI 池化更为简单,并且分类和回归器一起训练,不再使用 SVM.
Faster R-CNN:使用 Regional Proposal Network.
YOLO:划分为 \(13\times 13\) 个框,每个框提 \(6\) 个方案,每个方案包括真实框的大小及其置信度,并每个框做物体辨别识别.
图像分割的 Dice 系数:\(\frac{2|A\cap B|}{|A|+|B|}\). 值都是 \(0,1\) 时等于 \(\frac{2|A\cdot B|}{|A|^2+|B|^2}\).
图像分割使用 Mirror Padding 防止丢失边缘信息.
图像分割的损失加权:给边缘增加权重,根据物体大小调整权重.
Vanilla GAN 使用了全连接,DC GAN 使用了卷积. 显然相比之下前者就很 L.
相比于GAN,使用均方误差的 VAE 容易忽略面积较小的重要特征.
Cycle GAN:

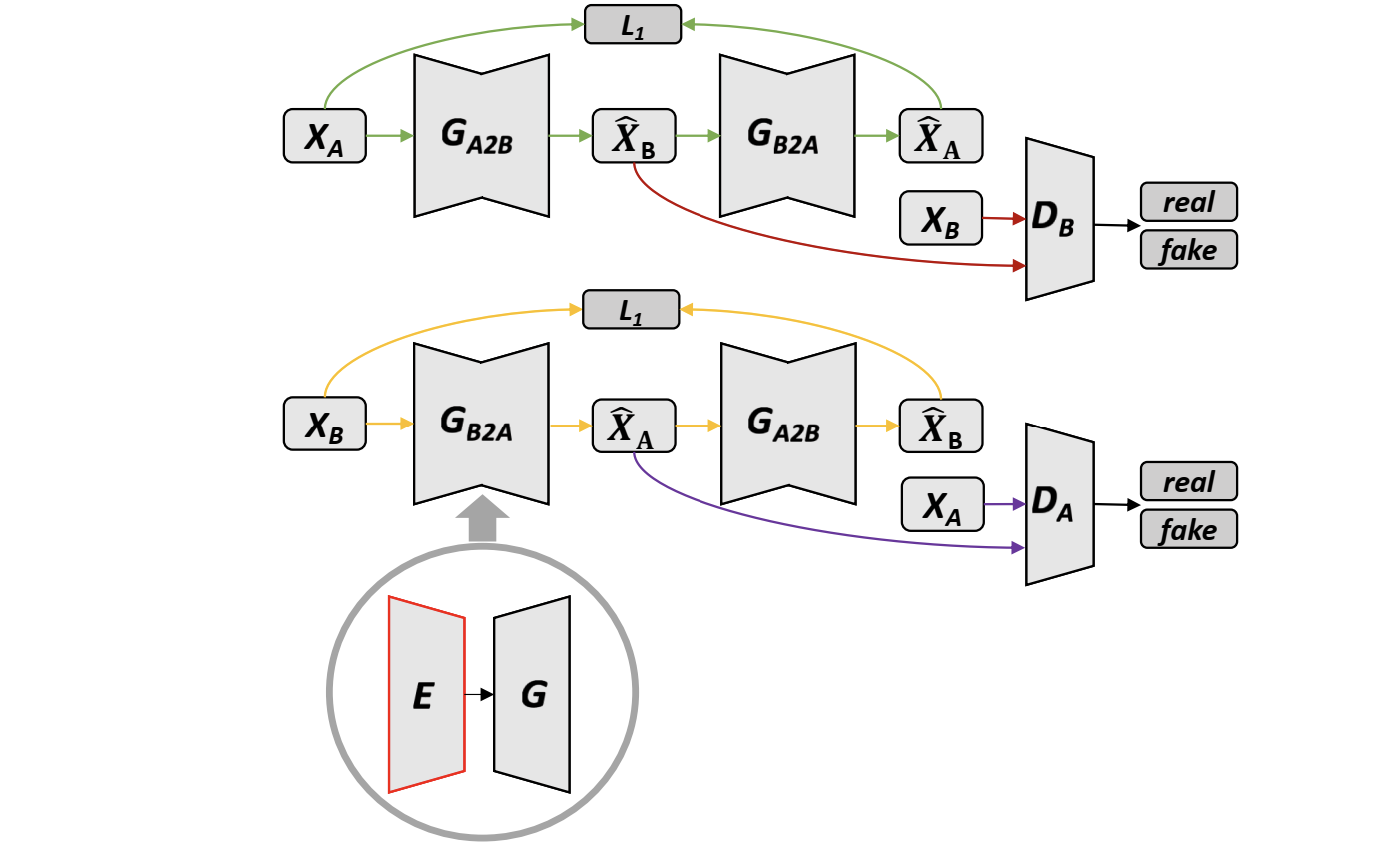
Cycle Consistency Loss:使得 \(A\) 和 \(G(A)\) 确实在表达类似的事.
Identity Loss:加入 \(||A-G(A)||_1\),使得不会过度翻译(比如真实照片蓝色偏多导致把黄色的画翻译成蓝色了).
One-hot vector:维度灾难,词之间独立.
Bags of words:维度灾难,忽略了时序.
Continuous Bags of words(CBOW):根据上下文预测中间的词.
Skip Gram:通过中间词预测上下文. 预测每个词是否属于上下文,使用 Sigmoid. 直接对所有词的话样本太多了,于是使用随机采样若干个正样本以及负样本.
天气预测是 Many to Many 的同步模型,翻译是异步的.
LSTM:遗忘门 \(f_t\),输入门 \(i_t\)(\(c'=f\odot c+i\odot \hat c\)),输出门 \(o_t\)(\(h=o\odot c'\)).
One to many 的损失可以使用所有步的平均损失. 网络是 Softmax 输出,可以使用 Top-K 采样获得多种描述句子.
同步 Many to Many 训练时要预先定义一个合适的序列长度.